What to do when you have private, even anonymous data as part of your analysis?
In economics, it is not uncommon to have data that are so private that the provider cannot be named. Firms (because usually these are firms) may be unwilling to reveal themselves in the analysis. Sometimes, this also applies to locations, when revealing the location might reveal sensitive information, or might compromise a follow-up study.
Of course, it is the first claim a fraudster would make, too. So how can we help legitimate authors separate themselves from the fraudsters, and still publish interesting and real research in journals?
The AEA’s policy on private data
The AEA Data and Code Availability Policy asks that authors provide access to all data used in a published paper. But it also acknowledges that there may be cases where data cannot be shared.
In rare cases where any of requirements (i)-(iv) above cannot be met due to valid constraints beyond the authors’ control, the AEA data editor and the journal editor may choose to modify the requirement(s), and such modifications will be noted in the article acknowledgements. However, in these cases the source of the data must still be disclosed to the AEA data editor prior to final acceptance of the paper.
How often does this happen?
A legitimate question is: does this happen often? The answer is no. Upon ingest, data access is classified into five categories: included (fully open data), and four categories of restricted access, going from “very easy to access” to “very difficult”.1
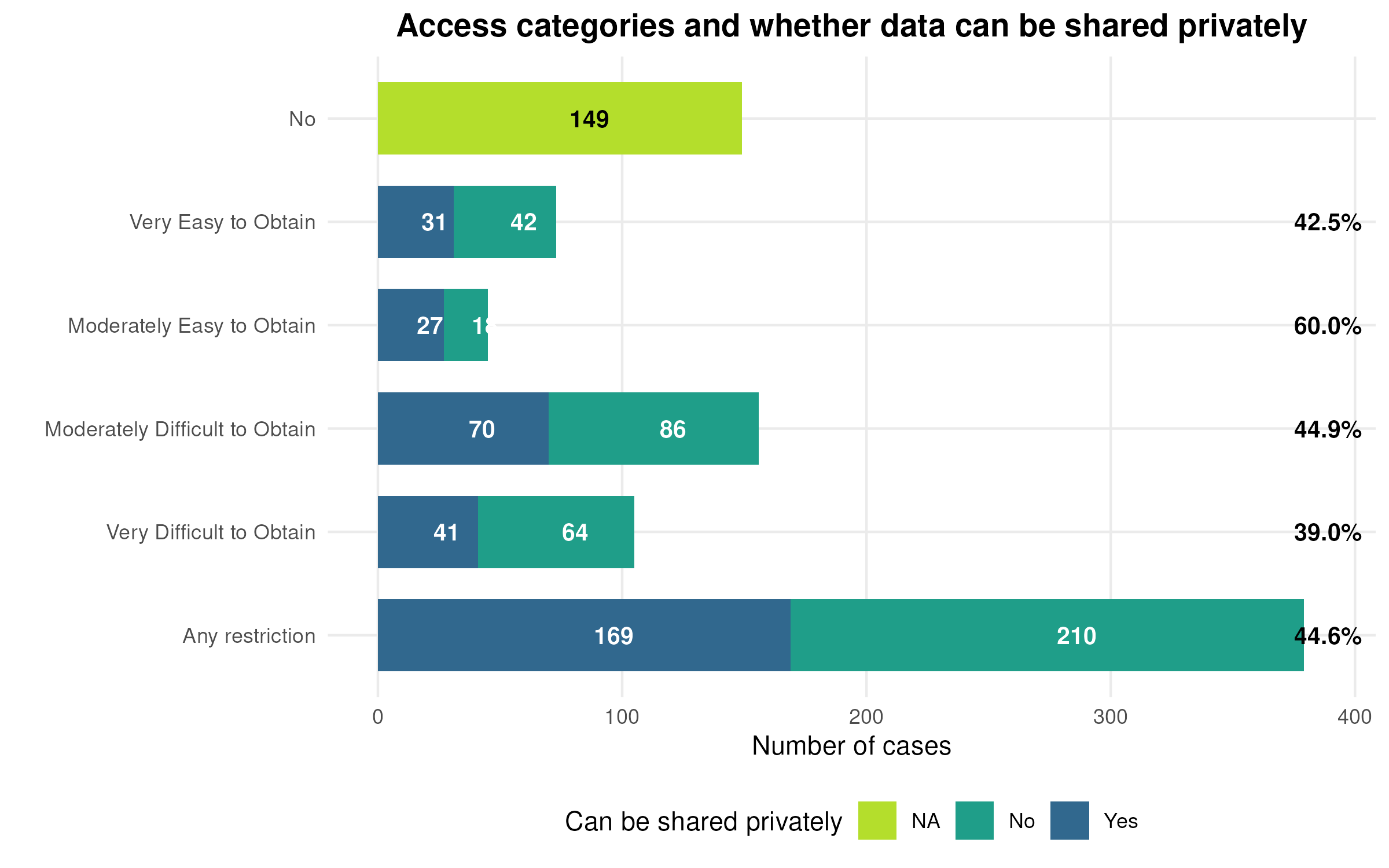
The “anonymous data” obviously falls into the last category, and in the last twelve months, we’ve had 5 such cases.
What do we then do?
Data provision
In a nutshell, our first preference is that authors are allowed to share the data with us, but not-for-publication. This means that we will have access to the data, and can run code against the data, but won’t publish the data.2
We provide a secure upload link, different from the draft deposit. Readers can view our template email with which we reach out to authors at here. Of course, authors should check with their data provider if provision of data is OK. We can also sign a non-disclosure agreement (NDA) if necessary (referenced in the email), but we stand by our word, and most authors take us up on that.
Name of the provider
For the name of the company, we may sign a separate NDA, to protect both us and the authors. Again, we have an SOP (Standard Operating Procedure) for that; here’s the (separate) template email for that. Important: the data provider should be aware of us signing the NDA, as we will publish the fact that the authors revealed the name to me.
Verification
Usually, I then contact the data provider, or a representative of the provider, directly. I keep no records of identity or other means of contact, and usually make video or phone calls, possibly using WhatsApp or Signal. I validate the representative’s identity through independent means (are they really who they claim to be). I ask questions regarding the authors’ access to the data: Did they actually get access? How? Can others get access? Why is the provider’s identity meant to be secret?
Once I have satisfied my professional curiosity, I report back to the editor in charge of the paper, and convey my opinion regarding the legitimacy of the data provider and of the data. The editor then makes a decision on whether to proceed with publication. Once we have obtained the data, we proceed to verify computational reproducibility. We will also work with the authors to make the restrictions and possibilities clear in the README.
Publication
Once all the other pieces fall into place, and the article is published, readers can find this information (for now) in the title page footnote:
“As part of the reproducibility checks conducted by the AEA, the identity of the anonymous data provider was revealed to the Data Editor, who verified legitimacy of the data use agreement and of access to the data.”
Closing remarks
Our process is not perfect, and probably there are ways to game it. We don’t reveal all the checks that we do, which may also include checking the data content, and for consistency with public data. But we hope that this allows the readers to have some confidence in the research being presented. The authors, of course, should also be sure to write their publication in such a way that it can be replicated in other contexts. After all, their access to a single anonymous firm, city, municipality, etc. remains a “N of 1” case, very interesting, but in need of generalization. The paper and the replication package hopefully help with that.
-
The first pass at this is made by authors self-classifying their data, on the Data and Code Availability Form. We may revisit this once we’ve seen the replication package, and will recode this in our internal database. ↩
-
To be clear, we actually never publish data or code regardless of when or how authors have provided it. The authors publish their data and their code, but in a space that we make available. We never touch their draft deposits, only review them, and we certainly never add anything to it. In some rare cases, we may help the authors by removing files that should not be there (obvious junk files). ↩
Enjoy Reading This Article?
Here are some more articles you might like to read next: